The market for data warehousing is expected to grow at a CAGR of 24.5%, reaching $7.69 billion by 2028. One reason behind this growth will be the increasing demand for services such as machine learning and artificial intelligence (AI) which are expected to expand significantly before the end of this decade. Such growth underscores how necessary it is for businesses today to have effective management systems and analytic capabilities for their information. Today, we’ll be taking a deep dive into two popular data warehousing schemas, Star Schema and Snowflake Schema, exploring their strengths, weaknesses, and the key differences.
Business intelligence (BI) could not be complete without data warehousing. This practice allows an organization to consolidate all its different data sources into a single location where it can be stored conveniently and analyzed easily. Such storage is centralized at one point, enabling multiple advanced analytics and reporting or decision-making processes. Two of the most common data warehouse design approaches are Star Schema and Snowflake Schema.
Understanding the Popular Schemas in Data Warehousing Modeling?
Star schema and snowflake schema are data modeling techniques used in data warehousing. Moreover, these models help structure information so that query performance is optimized while data integrity is ensured simultaneously. Therefore, organizations looking forward to setting up their own warehouses must understand these differences alongside their respective advantages. This article will delve deep into star schema and snowflake schema, exploring the structures behind them and use cases that may apply to other business requirements, if any.

What is a Star Schema?
A star schema is a data warehouse and business intelligence commonly used database schema. It aims to simplify the management of information and optimize query performance. Also, the design of the star scheme features a central fact table that holds quantitative data such as sales or revenue while surrounded by dimension tables that define the dimensions of the facts (time, product, store). This configuration is called ‘star’ because it looks like one, with its arms extending from an inner point towards outer points.
Central Fact Table Surrounded by Dimension Tables
Fact Table: The core table contains measurable or quantitative information about events in star schemas. Consequently, every row in this table represents a unique event like sale or order placement; every column describes different aspects of the transaction including foreign keys linking to other tables called dimensions and numerical measures such as units sold, price per unit etc.
Dimensions Tables: These are descriptive attributes related to facts. Each dimension table is connected to the fact table through its foreign key. Dimension tables may be denormalized which implies redundancy for simplicity when querying them, hence improving performance.
Simple, Denormalized Structure
Star schemes are known for their simplicity and ease of use. Also, they have many copies of data in dimension tables, so users can access it without joining multiple times, thus creating faster queries. Due to its ease of use, ad hoc queries can be run quickly against this type of design, which makes them suitable for end-users and business analysts who need fast report-generation capabilities.
Example of a Star Schema in a Retail Scenario
Let’s consider a simple retail scenario where a company wants to analyze its sales data:
Fact Table: Sales
| Sales ID |
Date ID |
Product ID |
Store ID |
Sales Amount |
Quantity Sold |
| 1 |
20210101 |
101 |
1001 |
500.00 |
5 |
| 2 |
20210102 |
102 |
1002 |
300.00 |
3 |
Dimension Tables:
Date Dimension
| Date ID |
Date |
Month |
Quarter |
Year |
| 20210101 |
01-Jan-2021 |
Jan |
Q1 |
2021 |
| 20210102 |
02-Jan-2021 |
Jan |
Q1 |
2021 |
Product Dimension
| Product ID |
Product Name |
Category |
Brand |
Price |
| 101 |
Widget A |
Gadgets |
Brand X |
100.00 |
| 102 |
Widget B |
Gadgets |
Brand Y |
150.00 |
Store Dimension
| Store ID |
Store Name |
Location |
Region |
| 1001 |
Store 1 |
City A |
North |
| 1002 |
Store 2 |
City B |
South |
In this example:
- The Sales fact table captures each sale transaction, including the “SalesID”, “DateID”, “ProductID”, “StoreID”, “SalesAmount”, and “QuantitySold”.
- The Date Dimension provides details about the dates of transactions, allowing for time-based analysis.
- The Product Dimension includes product details such as name, category, brand, and price.
- The Store Dimension contains information about the store locations and regions.
This structure allows for efficient queries such as:
- Sales performance by store location.
By organizing data in this way, businesses can quickly generate insightful reports and perform detailed analyses, making the star schema an effective choice for data warehousing and business intelligence applications.

What is a Snowflake Schema?
A snowflake schema is a type of database schema employed in data warehousing and business intelligence. It is an extension of the star schema, where dimension tables are normalized into multiple related tables. The resultant structure is more intricate and hierarchical, resembling a snowflake.
Central Fact Table with Normalized Dimension Tables
Fact Table: Like the star schema, the fact table in a snowflake schema holds numeric data like sales or revenue. Every row represents an individual event or transaction and includes foreign keys that link to dimension tables.
Normalized Dimension Tables: In this design, we normalize dimension tables to eliminate redundancy. In other words, attributes within each dimension table are split into separate additional tables, which then connect back to the main one. This normalization creates many interrelated tables, offering better organization and structure for viewing information about data from different perspectives.
More Complex, Hierarchical Structure Resembling a Snowflake
The snowflake schema, with its normalized dimensions, is more complex than the star schema. While it minimizes repetition and maximizes the correctness of stored facts, it also requires careful planning and consideration. Users writing queries against these structures must perform numerous joins, leading to an increase in query complexity. The hierarchical nature of snowflakes allows for storing detailed records at lower levels within the hierarchy, making them useful for highly granular reporting over large volumes of historical transactional records across various dimensions.
Example of a Snowflake Schema in a Retail Scenario
Consider a retail company that wants to analyze its sales data. The snowflake schema for this scenario might include:
Fact Table: Sales
| Sales ID |
Date ID |
Product ID |
Store ID |
Sales Amount |
Quantity Sold |
| 1 |
20210101 |
101 |
1001 |
500.00 |
5 |
| 2 |
20210102 |
102 |
1002 |
300.00 |
3 |
Dimension Tables:
Date Dimension
| Date ID |
Date |
Month ID |
Quarter ID |
Year |
| 20210101 |
01-Jan-2021 |
1 |
1 |
2021 |
| 20210102 |
02-Jan-2021 |
1 |
1 |
2021 |
Month Dimension
Quarter Dimension
Product Dimension
| Product ID |
Product Name |
Category ID |
Brand ID |
Price |
| 101 |
Widget A |
1 |
1 |
100.00 |
| 102 |
Widget B |
1 |
2 |
150.00 |
Product Category Dimension
| Category ID |
Category |
| 1 |
Gadgets |
Brand Dimension
| Brand ID |
Brand |
| 1 |
Brand X |
| 2 |
Brand Y |
Store Dimension
| Store ID |
Store Name |
Location ID |
Region ID |
| 1001 |
Store 1 |
1 |
1 |
| 1002 |
Store 2 |
2 |
2 |
Location Dimension
| Location ID |
Location |
| 1 |
City A |
| 2 |
City B |
Region Dimension
| Region ID |
Region |
| 1 |
North |
| 2 |
South |
In this example:
- The Sales fact table captures each sale transaction, including the “SalesID”, “DateID”, “ProductID”, “StoreID”, “SalesAmount”, and “QuantitySold”.
- The Date Dimension is normalized into separate tables for months and quarters.
- The Product Dimension is normalized into tables for product categories and brands.
- The Store Dimension is normalized into tables for locations and regions.
This structure allows for detailed analysis and reporting, such as:
- Total sales by product category and brand.
- Sales trends by month and quarter.
- Sales performance by store location and region.
By organizing data in this hierarchical way, the snowflake schema reduces redundancy and improves data integrity, making it suitable for complex data environments and detailed analytical queries.

Star Schema vs Snowflake Schema: Key Differences
Criteria
|
Star Schema
|
Snowflake Schema
|
| Structure |
Simple and denormalized |
Complex and normalized |
| Fact Table |
Centralized fact table connected to dimension tables |
Centralized fact table with normalized dimension tables |
| Dimension Tables |
Single level, directly linked to the fact table |
Multi-level, normalized tables linked hierarchically |
| Data Redundancy |
High redundancy, less normalization |
Low redundancy, higher normalization |
| Query Performance |
Faster query performance due to fewer joins |
Slower query performance due to multiple joins |
| Ease of Use |
Easier to design and use |
More complex design and maintenance |
| Storage |
Requires more storage space due to redundancy |
Requires less storage space due to normalization |
| Flexibility |
Less flexible, harder to change |
More flexible, easier to extend and maintain |
| Use Case |
Suitable for small to medium-sized data warehouses |
Suitable for large and complex data warehouses |
| Example |
A sales database where dimensions like Time, Product, and Geography are directly linked to Sales facts |
A sales database where dimensions like Time, Product, and Geography are further broken down into sub-dimensions (e.g., Product Category, Country, Region) |

Advantages and Disadvantages of Star Schema and Snowflake Schema
Star Schema
Advantages
- Simplicity: The star schema’s simplest design enables easy understanding and usage. Due to its denormalized nature, it has fewer tables, promoting straightforward relationships between them, which in turn simplifies query creation and database management.
- Better Performance for Read-Heavy Queries: Compared to other types of schemas, this one performs better on read-centric queries because fewer joins are required when dealing with denormalized structures. This is especially useful when working with reporting or data analysis tasks.
- Ease of Use: Users find stars intuitive, making them user-friendly even if they need to be more technically inclined. This means business users can quickly understand what is going on, thus helping them work efficiently with their respective data models.
Disadvantages
- Higher Storage Requirements: Due to redundancy brought about by its denormalized structure, storage space is used up more than necessary, resulting in high costs associated with both storing and managing data volumes.
- Potential for Data Redundancy and Integrity Issues: When information resides at more than one location within a table (denormalization), updating such records becomes risky since it’s easy to have different versions lying around, leading to inconsistency errors during integrity checks.
Snowflake Schema
Advantages
- Reduced Redundancy: The snowflake schema eliminates duplicated entries by keeping related datasets separate across many linked tables. Thereby saving disk space for storing records without meaningful variations.
- Better Data Integrity: Through normalization, facts are stored in an orderly way that ensures consistency plus guards against anomalies. This could corrupt the whole dataset making some parts inaccurate while leaving others untouched.
- Efficient Storage: Since there isn’t much repetition involved, like in stars, snowflakes often require less memory than their counterparts. Making better use of available storage resources within organizations dealing with large amounts of structured information.
Disadvantages
- Complexity: Snowflakes introduce intricacy into database designs through additional relations and tables. This may span different levels, leading to difficulties comprehending or maintaining such systems.
- Slow Query Performance: Retrieving data across many indirectly connected tables can take longer than necessary due to multiple joins required by this schema type during query execution. This results in poor response times for read-intensive operations involving large datasets typically found in report-generation processes.
- Difficulties with Design and Maintenance: Creating snowflake schemas is more involved and requires advanced skills in normalization principles. This means that its implementation may be complicated. Thus, demanding meticulous planning from developers who must possess more profound knowledge about how databases should be optimized using these techniques.

What are the Applications of Star Schema?
Data Warehousing
Star schema is widely used in data warehousing environments when the main purpose is to perform read-heavy operations like reporting, data analysis, and business intelligence. This structure allows faster query performance through denormalization, which is important for these applications.
Example: A retail company uses a star schema to analyze sales across different regions, products, and time periods to identify trends and make informed choices about them.
Business Intelligence Tools
Star schemas can be easily integrated with Business Intelligence (BI) tools such as Tableau, Power BI, or QlikView. Because of the simple structure of star schemas, these tools can generate reports and dashboards without any difficulties.
Example: A financial institution uses Power BI for real-time reporting on transactional data and customer demographics.
Simple Reporting Systems
For organizations with more straightforward reporting needs, the star schema provides a user-friendly approach to data modeling that enables quick access to information.
Example: A small business uses a star scheme to track inventory levels and sales performance and quickly generate reports.

What Are the Applications of Snowflake Schema?
Complex Analytical Queries
The snowflake schema works best where complex analytical queries are performed. It also reduces redundancy by normalizing its structure, thus ensuring consistency of the information contained within it.
Example: A healthcare organization uses snowflake schema for detailed, accurate reporting while analyzing patient data, treatment outcomes, and medical history.
Large-Scale Data Warehouses
Commonly used in big warehouses to handle large amounts of multi-source data at once, snowflake schemas cater to normalization, which helps store and manage big datasets efficiently.
Example: Global e-commerce platform integrates different markets’ product categories’ customer segments’ etcetera by using Snowflake schema
Regulatory Compliance
The ability of the snowflake schema to maintain the integrity of information while supporting compliance with governance standards makes it suitable for industries with stringent regulations, such as finance or health care.
Example: A financial services provider employs a snowflake schema to manage transactional data to ensure compliance with global financial regulations.
Data Integration Projects
The snowflake schema can be used to normalize and harmonize data during projects involving the integration of diverse sources, thus enabling comprehensive analysis.
Example: A multinational corporation uses a snowflake schema for consolidated financial reporting strategic planning by integrating various subsidiary company records.

Choosing the Right Schema for Your Needs: Factors to Consider
The choice between star and snowflake schemas is an important one that can significantly affect the efficiency and effectiveness of a data warehouse. Here are some things to think about.
1. Complexity of Data and Relationships
Star Schema: It is most successful in austere data environments where relationships are uncomplicated and easily defined. This works well when dimension tables are small and not deeply nested.
Snowflake Schema: It is great for complex data environments with many dimensions and intricate relationships. It works best where normalization is needed to minimize redundancy and preserve data integrity.
2. Performance Requirements for Queries
Star Schema: Read-heavy operations such as reporting or analysis usually perform better under this schema because of its denormalized nature, which reduces joining needs.
Snowflake Schema: Multiple joins between tables may slow down query performance. However, it can be optimized for specific queries through indexing.
3. Storage Constraints and Efficiency Needs
Star Schema: More storage space is used due to redundant copies of records, but this may speed up retrieval times, especially when large volumes are involved.
Snowflake Schema: Data redundancy is reduced through normalization, making it more storage efficient. This is crucial when dealing with big datasets or when there is concern over storage costs.
4. Ease of Use and Maintenance Capabilities
Star Schema: Simplicity in design, understanding, and usage, thus suitable for organizations lacking adequate database management resources. Maintenance requires fewer tables plus more straightforward relationship definitions only.
Snowflake Schema: A normalized structure requires a deeper understanding of how databases should be designed and maintained since multiple tables are involved. Thus, greater effort is required when managing alterations alongside updates.
Practical Tips for Selecting the Right Schema
1. Start with a Star Schema for Simplicity and Performance
For many businesses, especially those venturing into fresh or lightweight warehousing data loads, beginning with a star schema will always be the best decision ever. It has straightforwardness in design, ease of usage, and good performance levels for typical reporting and analysis duties.
2. Consider a Snowflake Schema for Complex, Multidimensional Data
In situations where your data environment is multidimensional, with complicated relationships between various attributes that demand extensive normalization. The use of a snowflake schema would be ideal. This happens mostly among big enterprises with advanced informational requirements that need the utmost accuracy of facts plus minimum repetition.

Case Study: Transforming Healthcare Through Data-Driven Insights
Client Overview
This client is among the best healthcare providers looking forward to bettering their data analytic capabilities to improve patient care, operational efficiency, and decision-making. They needed help managing large amounts of data from different sources, which required a robust data architecture to optimize their analysis.
The Problem
The main issues this organization faced were redundant data, inconsistent data quality, and slow retrieval processes. Their existing model was not scalable enough or flexible to deal with the rising number of health-related records. They wanted a system that could give them one view of what they have without compromising performance or integrity.
Solution
To solve these challenges, Kanerika introduced the Snowflake Schema. The normalized structure of the snowflake schema was suitable for complex environments with many types of information like theirs. Some steps taken under this approach include:
- Normalization of Data: Kanerika created multiple related tables where each record was stored once, thus reducing redundancy while ensuring referential integrity between them. For example, no two rows can have dissimilar values for primary key columns.
- Better Query Performance: By minimizing duplication of facts and figures in Snowflakes’ design during querying, fewer rows will be scanned. This leads to faster response time, especially when reading lots of reports or analyzing massive datasets, which was the usual scenario at this company.
- Scalable And Flexible Solution: If more sources come into play or new needs arise, adding extra components will be easy thanks to the architectural model used here, the snowflake schema.
- Power BI Integration: Snowflakes’ integration with the Power BI tool by Kanerika made it possible to create interactive dashboards and real-time reporting. This enables a quick understanding of how healthy resources are being utilized, operationally efficient healthcare services are delivered, and patient care outcomes are achieved.
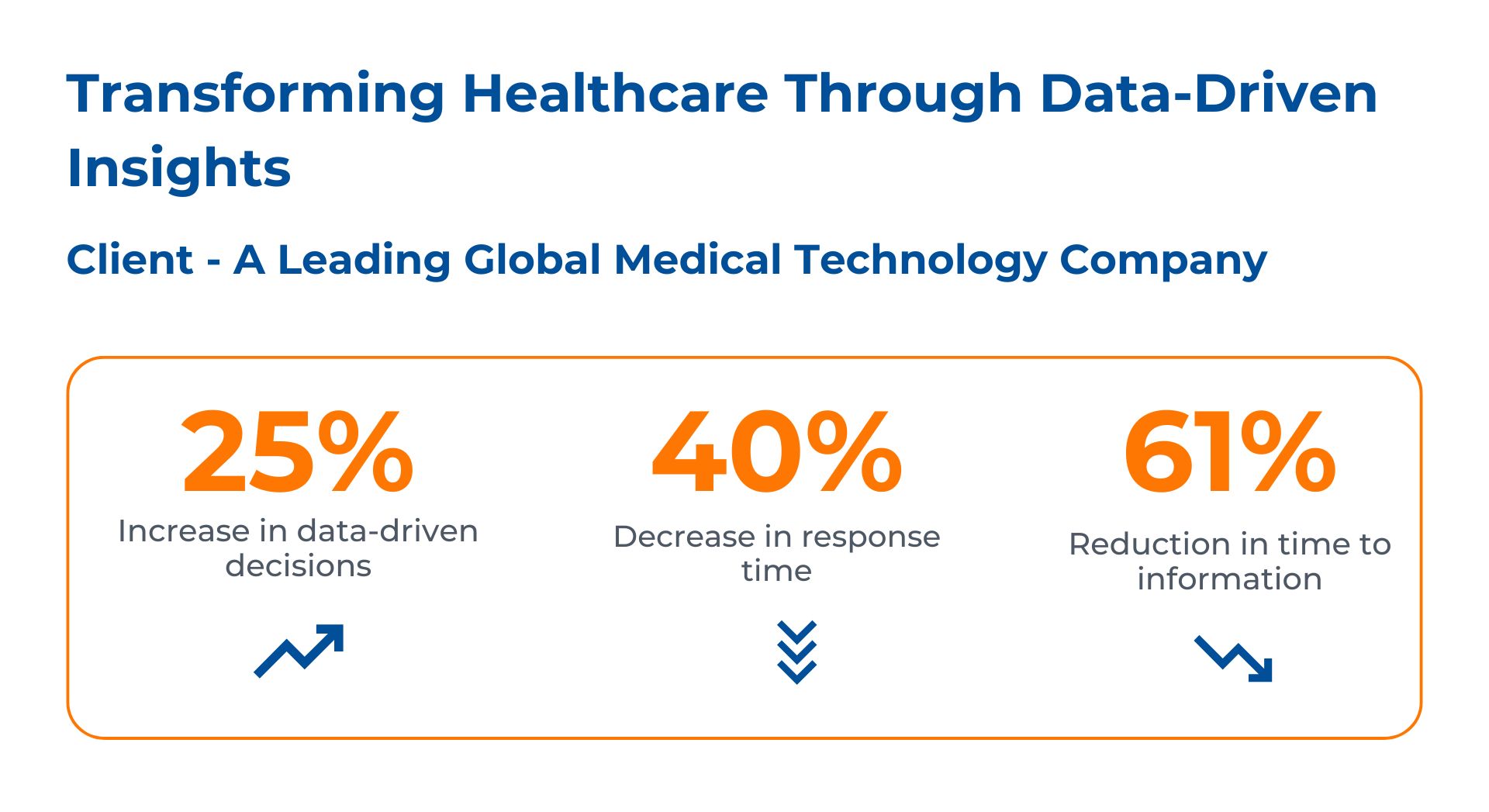
Outcomes
- Better Data Accuracy: Snowflakes’ structured approach ensures that all records are accurate since there is only one place where they should reside.
- Improved Performance: Because fewer rows need to be read during querying, reports will load faster, thus saving time for users who want quick access to these documents.
- Scalable and Flexible Data Model: With this design, organizations can handle increasing volumes of health-related information and accommodate changes in data requirements without much hassle.
- More Actionable Insights: The integration allows for the creation of interactive dashboards, which means that decision-makers within medical facilities can see what is happening on the ground through various graphical representations while still being able to drill down into specific points.

Elevate Your Data Management with Kanerika’s Cutting-edge Solutions
In today’s data-driven world, efficient data management is the key to business success. At Kanerika, we specialize in delivering top-notch data warehousing solutions that help businesses manage their data with precision and ease. Our expertise in both Star Schema and Snowflake Schema designs ensures that your data is organized, accessible, and ready for analysis.
By leveraging these advanced schema designs, we eliminate data redundancy and improve query performance, enabling your business to make informed decisions faster. Whether you need the simplicity and speed of a Star Schema or the normalized structure of a Snowflake Schema, Kanerika has got you covered.
Our solutions are tailored to enhance your business operations, streamline data workflows, and support your growth. Choose Kanerika to transform your data management processes and scale your business to new heights. Let us help you unlock the full potential of your data today!

FAQs
[faq-schema id=”39137″]


