Consider a retail giant that manages millions of transactions daily. Their success hinges on how swiftly and accurately they can process this data to restock items, optimize marketing strategies, and enhance customer experiences. However, without a well-optimized data pipeline, they risk delays in insights, potential data errors, and, ultimately, lost opportunities.
Data pipeline optimization is the process of refining these crucial systems to ensure they operate efficiently, accurately, and at scale. By streamlining how data is collected, processed, and analyzed, businesses can transform raw data into actionable insights faster than ever before, driving smarter decisions and more effective outcomes.
Understanding Data Pipelines
1. Components and Architecture
A data pipeline is a crucial system that automates the collection, organization, movement, transformation, and processing of data from a source to a destination. The primary goal of a data pipeline is to ensure data arrives in a usable state that enables a data-driven culture within your organization. A standard data pipeline consists of the following components:
- Data Source: The origin of the data, which can be structured, semi-structured, or unstructured data
- Data Integration: The process of ingesting and combining data from various sources
- Data Transformation: Converting data into a common format for improved compatibility and ease of analysis
- Data Processing: Handling the data based on specific computations, rules, or business logic
- Data Storage: A place to store the results, typically in a database, data lake, or data warehouse
- Data Presentation: Providing the processed data to end-users through reports, visualization, or other means
The architecture of a data pipeline varies depending on specific requirements and the technologies utilized. However, the core principles remain the same, ensuring seamless data flow and maintaining data integrity and consistency.
2. Types of Data Handled
Data pipelines handle various types of data, which can be classified into three main categories:
- Structured Data: Data that is organized in a specific format, such as tables or spreadsheets, making it easier to understand and process. Examples include data stored in relational databases (RDBMS) and CSV files
- Semi-structured Data: Data that has some structure but may lack strict organization or formatting. Examples include JSON, XML, and YAML files
- Unstructured Data: Data without any specific organization or format, such as text documents, images, videos, or social media interactions
These different data formats require custom processing and transformation methods to ensure compatibility and usability within the pipeline. By understanding the various components, architecture, and data types handled within a data pipeline, you can more effectively optimize and scale your data processing efforts to meet the needs of your organization.

Optimization Techniques for Data Pipelines
1. Data Partitioning and Bucketing
One effective optimization technique to improve the performance and scalability of your data pipeline is data partitioning. By dividing your dataset into smaller, more manageable pieces, you can process and analyze the data more efficiently. It helps reduce the amount of data read while querying and enhances performance.
Another related approach is bucketing. This technique involves grouping or organizing data in your partition based on specific criteria, such as values, ranges, or functions. Bucketing on columns with high cardinality could help decrease data shuffling during your Spark or Scala workloads.
Here are some benefits of data partitioning and bucketing:
- Improved query performance: Fewer data read from the disk during each query
- Better scalability: Partitioning enables parallel processing, which can help scale out your processing capabilities
- Reduced data shuffling: By properly bucketing your dataset, you can avoid expensive data shuffling processes, which in turn reduces the overall cost of your data pipeline
2. Parallel Processing and Distribution
Utilizing parallel processing and distribution techniques is another way to optimize your data pipeline for enhanced performance, reliability, and cost-effectiveness. By allowing multiple tasks to run concurrently, you can process large volumes of data more quickly and efficiently.
In the case of parallel processing, you split your data and perform operations on separate partitions simultaneously. This approach also helps to distribute the workload evenly across available resources, such as CPU cores or clusters, improving overall system performance.
In order to achieve these benefits:
- Identify and divide your dataset into smaller, independent sections
- Design your pipeline to process these sections simultaneously, using appropriate tools and frameworks like Spark or Scala
- Distribute the workload evenly across available resources and manage it in real time for optimal performance
Remember, parallel processing and distribution are particularly beneficial when:
- Processing large datasets: By parallelizing your operations, you can process massive amounts of data more quickly and efficiently.
- Scale-out is required: If your data pipeline needs to be scaled out, these techniques help ensure that your system continues running smoothly as the dataset grows.

Performance Metrics and Tuning Your Data Pipeline
1. Identifying Bottlenecks
To optimize your data pipeline, you need to identify and address any bottlenecks in performance. Start by establishing a baseline for your pipeline, which includes current performance metrics such as execution time, resource utilization, and data throughput. Monitoring these metrics helps you identify performance bottlenecks and makes it easier to locate specific areas in the pipeline that need improvement.
A few strategies to identify bottlenecks include:
- Thoroughly testing your pipeline to assess any data ingestion and processing issues
- Analyzing data flow and ensuring that each stage efficiently processes and transfers data
- Monitoring system resource utilization and adjusting parameters to minimize any bottlenecking
Once you have identified the bottlenecks, you can apply appropriate tuning strategies to improve your pipeline’s performance.
2. Memory Management and File Size Optimization
Effective memory management and file size optimization are crucial for optimizing a data pipeline’s performance. Here are some best practices to improve memory management and file size optimization:
- File size: Aim for optimal file sizes, such as 128MB per file, to achieve a balance between storage requirements and read/write performance. If needed, you can use tools like Auto Optimize to automatically compact your smaller files into larger ones during individual writes
- Memory allocation: Allocate appropriate memory resources for each stage in the pipeline and ensure that they aren’t being excessively used or underutilized
- Data partitioning: Optimize your data partitioning by dynamically sizing Apache Spark partitions based on the actual data. An ideal partition size can help balance memory usage and improves pipeline performance
- Garbage collection: Regularly perform garbage collection to clean up unused objects and free up memory, thereby improving overall performance
By following these best practices and consistently monitoring performance metrics, you can efficiently manage memory and file sizes in your data pipeline. This will ultimately lead to better performance and a more seamless data flow.

Handling Data Quality and Consistency
1. Ensuring Accuracy and Reliability
Maintaining high data quality and consistency is essential for your data pipeline’s efficiency and effectiveness. To ensure accuracy and reliability, conducting regular data quality audits is crucial. These audits involve a detailed examination of the data within your system to ensure it adheres to quality standards, compliance, and business requirements. Schedule periodic intervals for these audits to examine your data’s accuracy, completeness, and consistency.
Another strategy for improving data quality is by monitoring and logging the flow of data through the pipeline. This will give you insight into potential bottlenecks that may be slowing the data flow or consuming resources. By identifying these issues, you can optimize your pipeline and improve your data’s reliability.
2. Handling Redundancy and Deduplication
Data pipelines often encounter redundant data and duplicate records. Proper handling of redundancy and deduplication plays a vital role in ensuring data consistency and compliance. Design your pipeline for fault tolerance and redundancy by using multiple instances of critical components and resources. This approach not only improves the resiliency of your pipeline but also helps in handling failures and data inconsistencies.
Implement data deduplication techniques to remove duplicate records and maintain data quality. This process involves:
- Identifying duplicates: Use matching algorithms to find similar records
- Merging duplicates: Combine the information from the duplicate records into a single, accurate record
- Removing duplicates: Eliminate redundant records from the dataset

Cost Management and Efficiency
1. Resource Utilization and Efficiency
Efficient use of resources is vital for building cost-effective and performant data pipelines. By carefully tuning resource consumption settings, you can achieve significant cost savings without sacrificing functionality. Here are some key points to consider:
- Optimize workloads: Analyze your data workloads and allocate resources based on their needs. Identify compute-intensive tasks and ensure they have sufficient resources while avoiding over-provisioning for less demanding tasks
- Monitor resource usage: Use monitoring tools to gain real-time insights into how resources are consumed. This can help you identify inefficiencies and make adjustments as needed, such as adjusting the throughput capacity or memory allocation
- Data partitioning: Partition your data effectively to improve parallelism and reduce the amount of unnecessary I/O, resulting in improved processing speed and lower storage costs. This also aids in distributing resources evenly across your data pipeline
2. Scaling and Provisioning
Proper management of scaling and resource provisioning is essential to maintain data pipeline efficiency and flexibility in a cost-effective manner. Follow these best practices to ensure optimal resource allocation:
- Adaptability: Design your data pipelines to be easily scalable, allowing you to handle fluctuating workloads and growing data volumes without disrupting the system
- Automated scaling: Implement automated scaling solutions for your data processes, which can help maintain a balance between performance and cost. This enables you to allocate resources based on actual demand rather than relying on fixed limits
- Evaluate resource options: Regularly review available cloud and infrastructure resource options to identify potential cost savings and efficiency improvements. Researching new pricing models, instance types, and storage solutions could potentially reveal better alternatives for your data pipeline
In summary, achieving cost management and efficiency in your data pipeline requires a thorough understanding of resource utilization and the ability to adapt to changing workloads. By taking the aforementioned steps and maintaining a vigilant outlook, you can maximize the value of your data pipeline while minimizing costs.

Security, Privacy, and Compliance of Data Pipelines
1. Data Governance and Compliance
Effective data governance plays a crucial role in ensuring compliance with various regulations such as GDPR and CCPA. It is essential for your organization to adopt a robust data governance framework, which typically includes:
- Establishing data policies and standards
- Defining roles and responsibilities related to data management
- Implementing data classification and retention policies
- Regularly auditing and monitoring data usage and processing activities
By adhering to data governance best practices, you can effectively protect your organization against data breaches, misconduct, and non-compliance penalties.
2. Security Measures and Data Protection
In order to maintain the security and integrity of your data pipelines, it is essential to implement appropriate security measures and employ effective data protection strategies. Some common practices include:
- Encryption: Use encryption techniques to safeguard data throughout its lifecycle, both in transit and at rest. This ensures that sensitive information remains secure even if unauthorized access occurs
- Access Control: Implement strict access control management to limit data access based on the specific roles and responsibilities of employees in your organization
- Data Sovereignty: Consider data sovereignty requirements when building and managing data pipelines, especially for cross-border data transfers. Be aware of the legal and regulatory restrictions concerning the storage, processing, and transfer of certain types of data
- Anomaly Detection: Implement monitoring and anomaly detection tools to identify and respond swiftly to potential security threats or malicious activities within your data pipelines
- Fraud Detection: Leverage advanced analytics and machine learning techniques to detect fraud patterns or unusual behavior in your data pipeline

Emerging Tools and Technologies to Enable Data Pipelines
1. Programming Languages and Frameworks
- Python: The Python programming language is a popular choice for data engineering tasks, thanks to its powerful libraries, such as Pandas. It is widely used for data manipulation, allowing you to clean, filter, and aggregate your data quickly and easily
- Rust: Rust is an emerging programming language that offers high-speed performance and memory safety. It is becoming a popular choice for implementing high-performance data pipelines, particularly when dealing with large-scale data processing tasks
- Scala: Scala, a programming language built on the Java Virtual Machine (JVM), is widely used in tandem with Apache Spark due to its ability to handle large datasets efficiently
2. Data Processing Platforms and Solutions
- Apache Spark: Spark is an open-source big data processing framework that provides powerful capabilities for data processing, machine learning, and real-time analytics. It allows you to easily scale and parallelize your data processing tasks for faster results
- Databricks: Databricks is a unified data analytics platform that simplifies and accelerates data processing and machine learning tasks. Built on top of Apache Spark, it provides a series of optimizations and improvements that make it an excellent choice for handling complex data pipelines
- Hive: Apache Hive is a data warehouse solution that can process structured and semi-structured data. It provides a SQL-like query language, allowing you to perform data analysis and transformations using familiar syntax
Informatica to DBT Migration
When optimizing your data pipeline, migrating from Informatica to DBT can provide significant benefits in terms of efficiency and modernization.
Informatica has long been a staple for data management, but as technology evolves, many companies are transitioning to DBT (for more agile and version-controlled data transformation. This migration reflects a shift towards modern, code-first approaches that enhance collaboration and adaptability in data teams.
Moreover, transitioning from a traditional ETL (Extract, Transform, Load) platform to a modern data transformation framework leverages SQL for defining data transformations and runs directly on top of a data warehouse. This process aims to modernize the data stack by moving to a more agile, transparent, and collaborative approach to data engineering.
Here’s what the migration typically entails:
- Enhanced Agility and Innovation: DBT transforms how data teams operate, enabling faster insights delivery and swift adaptation to evolving business needs. Its developer-centric approach and use of familiar SQL syntax foster innovation and expedite data-driven decision-making
- Scalability and Elasticity: DBT’s cloud-native design integrates effortlessly with modern data warehouses, providing outstanding scalability. This adaptability ensures that organizations can manage vast data volumes and expand their analytics capabilities without performance hitches
- Cost Efficiency and Optimization: Switching to DBT, an open-source tool with a cloud-native framework, reduces reliance on expensive infrastructure and licensing fees associated with traditional ETL tools like Informatica. This shift not only trims costs but also optimizes data transformations, enhancing the ROI of data infrastructure investments
- Improved Collaboration and Transparency: DBT encourages better teamwork across data teams by centralizing SQL transformation logic and utilizing version-controlled coding. This environment supports consistent, replicable, and dependable data pipelines, enhancing overall effectiveness and data value delivery

Key Areas to Focus:
- Innovation: Embrace new technologies and methods to enhance your data pipeline. Adopting cutting-edge tools can result in improvements related to data quality, processing time, and scalability
- Compatibility: Ensure that your chosen technology stack aligns with your organization’s data infrastructure and can be integrated seamlessly
- Scalability: When selecting new technologies, prioritize those that can handle growing data volumes and processing requirements with minimal performance degradation
When migrating your data pipeline, keep in mind that dbt also emphasizes testing and documentation. Make use of dbt’s built-in features to validate your data sources and transformations, ensuring data correctness and integrity. Additionally, maintain well-documented data models, allowing for easier collaboration amongst data professionals in your organization.
Migration Approach for Transitioning from Informatica to DBT
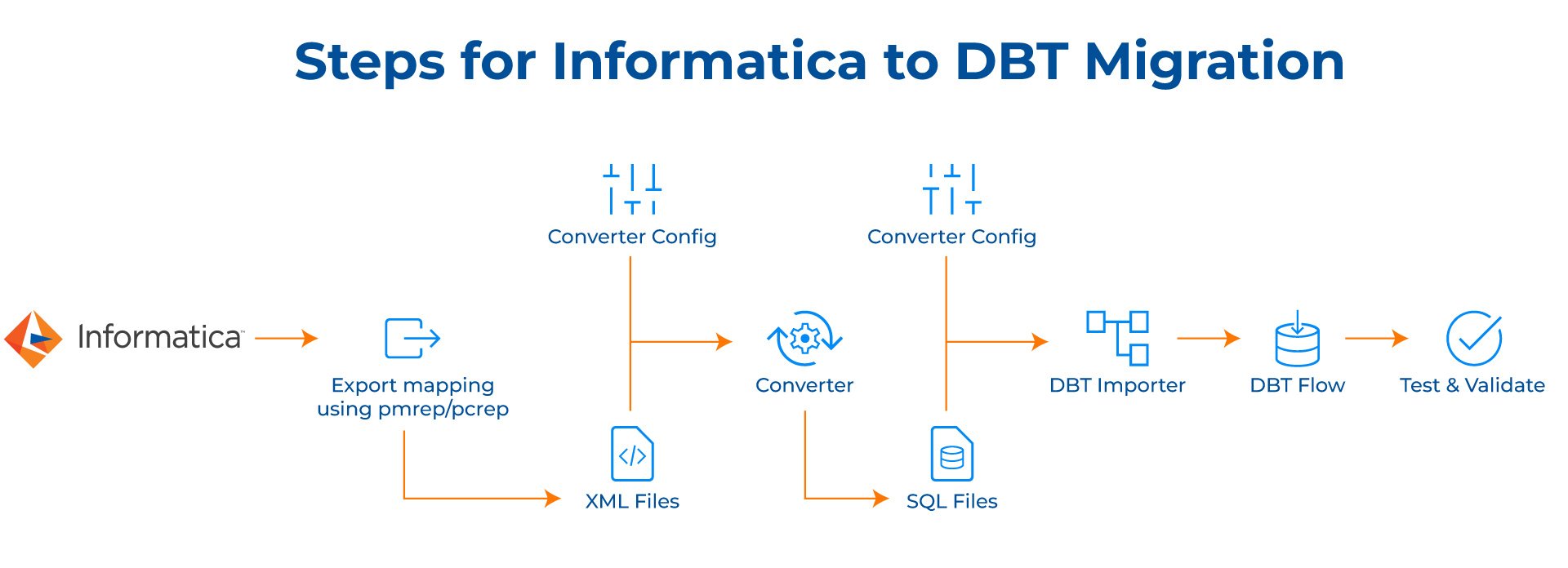
1. Inventory and Analysis
Catalog all Informatica mappings, including both PowerCenter and IDQ. Perform a detailed analysis of each mapping to decipher its structure, dependencies, and transformation logic.
2. Export Informatica Mappings
Utilize the pmrep command for PowerCenter and pcrep for IDQ mappings to export them to XML format. Organize the XML files into a structured directory hierarchy for streamlined access and processing.
3. Transformation to SQL Conversion
Develop a conversion tool or script to parse XML files and convert each transformation into individual SQL files. Ensure the conversion script accounts for complex transformations by mapping Informatica functions to equivalent Snowflake functions. Structure SQL files using standardized naming conventions and directories for ease of management.

4. DBT Importer Configuration
Create a DBT importer script to facilitate the loading of SQL files into DBT. Configure the importer to sequence SQL files based on dependencies, drawing from a configuration file with Snowflake connection details.
5. Data Model and Project Setup
Define the data model and organize the DBT project structure, including schemas, models, and directories, adhering to DBT best practices.
6. Test and Validate
Conduct comprehensive testing of the SQL files and DBT project setup to confirm their correctness and efficiency. Validate all data transformations and ensure seamless integration with the Snowflake environment.
7. Migration Execution
Proceed with the migration, covering the export of mappings, their conversion to SQL, and importing them into DBT, while keeping transformations well-sequenced. Monitor the process actively, addressing any issues promptly to maintain migration integrity.
8. Post-Migration Validation
Perform a thorough validation to verify data consistency and system performance post-migration. Undertake performance tuning and optimizations to enhance the efficiency of the DBT setup.
9. Monitoring and Maintenance:
Establish robust monitoring systems to keep a close watch on DBT workflows and performance. Schedule regular maintenance checks to preemptively address potential issues.
10. Continuous Improvement:
Foster a culture of continuous improvement by regularly updating the DBT environment and processes based on new insights, business needs, and evolving data practices.
Choosing Kanerika as Your Migration Partner
When it comes to data pipeline optimization, Kanerika has proven itself to be a reliable and innovative migration partner that can help you achieve enhanced performance and maximize returns on your data. Our expertise in cloud migration and data engineering technologies makes us the ideal choice for handling your data requirements.
Our team is proficient in various popular programming languages and tools like Python, Rust, Scala, Apache Spark, Hive, and Pandas. We effectively utilize these technologies to design and implement perfect data pipelines that cater to your specific business needs.
One of our strengths lies in our ability to work with the latest big data processing frameworks, such as Databricks and Apache Spark. These powerful tools allow for efficient and scalable data processing, enabling your business to make data-driven decisions with ease.
Kanerika’s data pipeline automation skills boost the efficiency of your data processing pipelines and minimize the likelihood of errors. With their commitment to providing seamless data migration solutions and optimizing data pipelines, you can trust Kanerika to deliver top-notch services that align with your data management objectives.
Case Study- How did Kanerika Enable a Leading Retailer Migrate from Informatica to DBT
Client Profile:
A leading global retailer with over 500 stores in 30 countries, had relied on Informatica for its data management needs for over a decade. With a diverse product range and a complex supply chain, their data infrastructure needed to be highly efficient to keep pace with dynamic market demands and the growing need for real-time analytics.
Challenges:
- Scalability and Flexibility: The existing Informatica setup was increasingly cumbersome to scale with their business growth and lacked the flexibility needed for rapid changes
- Collaboration and Version Control: The data team struggled with collaboration due to the GUI-based interface of Informatica, which also posed challenges in version control and tracking changes over time
- Cost Efficiency: High licensing costs associated with Informatica were becoming a financial burden as the client looked to expand its data operations
Solution:
The client decided to migrate from Informatica to DBT, attracted by its capabilities for code-first data transformation, which facilitates better version control, easier collaboration through integration with tools like GitHub, and its ability to run on top of the existing data warehouse infrastructure, reducing the need for additional computing resources.
Implementation Steps:
- Initial Assessment and Planning: Conducted a thorough assessment of the existing data pipelines and architectures in Informatica
- Schema Conversion and Script Translation: Converted all ETL scripts from Informatica to DBT models, ensuring that transformations were accurately translated into SQL and Python, as used in DBT
- Testing and Validation: Rigorous testing phases to ensure data integrity and performance matched or exceeded the previous setup with Informatica
- Training and Onboarding: Provided comprehensive training for the client’s data team on DBT, focusing on best practices for code development, version control, and workflow management

Outcomes
- Cost Reduction: 40% reduction in data management costs.
Speed of Deployment: 70% improvement in deployment times.
Productivity Increase: 50% increase in team productivity.
This migration from Informatica to DBT enabled the client to enhance its data operations significantly, proving that modern, flexible, and collaborative tools like DBT are essential for companies aiming to thrive in today’s data-driven environment.
Frequently Asked Questions
[faq-schema id=”35973″]


