Have you ever wondered how Netflix seems to know exactly what movie you’d like to watch next, or how your email service filters out spam so effectively? These everyday conveniences are powered by machine learning algorithms. Machine learning, a subset of artificial intelligence, allows computers to learn from data and improve over time, essentially teaching them to make decisions based on patterns and previous experiences.
The global Machine Learning (ML) market is expected to reach US$ 31.36 million by 2028, growing at a Compound Annual Growth Rate (CAGR) of 33.6% during the period from 2022 to 2028. This explosive growth highlights the increasing reliance on ML algorithms across various industries, from healthcare and finance to retail and automotive.
Many of the modern technological advances are built on the foundation of machine learning algorithms. Without explicit programming, they allow computers to make decisions, learn from data, and get better over time. Machine learning algorithms are at the backbone of many advances, like self-driving cars, fraud detection, and Netflix movie recommendations. Understanding these algorithms is crucial for anyone looking to leverage the power of AI to solve real-world problems.
This blog explores several machine learning algorithm types, their applications, and how to turn unprocessed data into meaningful insights.
What Are Machine Learning Algorithms?
Machine learning (ML) algorithms are the computational procedures that enable computers to recognize patterns in data and draw conclusions from it. Rather than being explicitly coded with a set of rules, these algorithms use the input data to find patterns and predict outcomes. Supervised learning, unsupervised learning, and reinforcement learning are the three primary categories of machine learning algorithms.
Let’s take an example to understand this concept better: imagine you are a manager at an e-commerce company, and you want to predict whether a customer will buy a product based on their past behavior. You have a dataset that includes information about past customer transactions, such as:
- Age of the customer
- Income level
- Past purchase history
- Browsing history
- Time spent on the website
You can use a machine learning algorithm to analyze this data and predict future purchases. Here’s how it might work:
- Data Collection: Gather data about your customers’ interactions with your website.
- Feature Selection: Identify which features (age, income level, etc.) are relevant to the prediction.
- Algorithm Selection: Choose an appropriate algorithm, such as logistic regression, decision trees, or neural networks.
- Training the Model: Use historical data to train the algorithm. For example, in logistic regression, the algorithm will learn the coefficients that best predict whether a customer will make a purchase.
- Making Predictions: Apply the trained model to new data to predict whether a new customer will buy a product.

Understanding Different ML Algorithms
1. Supervised Learning Algorithms
Supervised learning involves training models on a dataset that includes both the inputs and the correct outputs. The goal is to learn a rule that maps inputs to outputs which can then be used to make predictions on new, unseen data.
Linear Regression
Used primarily for predicting outcomes where you expect a steady increase or decrease based on some characteristic. For instance, predicting salaries based on years of experience.
It finds a relationship that best fits a line through your data. As one variable increases, the outcome either increases or decreases along that line.
Use Cases: Predicting housing prices, stock market forecasting, and risk management
Logistic Regression
Best suited for binary outcomes, meaning the result is either one thing or another—like determining if an email is spam or not spam.
It predicts the likelihood of occurrence of an event by fitting data to a logistic curve. The outcome tells you the probability that the event will occur.
Use Cases: Spam detection, disease diagnosis, and credit scoring
Decision Trees
Useful for making a series of decisions that lead to a classification or value. Imagine deciding what to wear based on the weather; this algorithm operates similarly.
It breaks down data by making decisions based on asking a series of questions based on the features of the data.
Use Cases: Medical diagnosis, financial analysis, and customer segmentation
Support Vector Machines (SVM)
Used primarily for classification tasks like categorizing types of articles on a website.
It finds the best boundary that separates data points into different categories. This boundary is chosen to be the one where the distance from the nearest data points in each category is maximized.
Use Cases: Image recognition, bioinformatics, and text categorization
K-Nearest Neighbors (KNN)
Simple yet effective for classification and regression tasks, like recommending movies similar to the ones a user likes.
It looks at the closest data points (neighbors) and predicts the outcome based on the majority vote or average of these neighbors.
Use Cases: Pattern recognition, recommendation systems, and anomaly detection

2. Unsupervised Learning Algorithms
Unsupervised learning involves training models on data without labels. The goal here is to find structure within the data, like grouping similar items together.
K-Means Clustering
Useful for grouping data into a specified number (k) of groups. Think about segmenting customers into different groups based on purchasing behavior.
It groups data into k number of groups by minimizing the distance between data points and the center of their cluster.
Use Cases: Customer segmentation, market research, and image compression
Principal Component Analysis (PCA)
Often used to reduce the dimensionality of large datasets, by transforming a large set of variables into a smaller one that still contains most of the information.
It identifies the directions (principal components) along which the variation in the data is maximized. This helps to understand the structure of the data with fewer variables.
Use Cases: Data visualization, noise reduction, and feature extraction
Anomaly Detection
Used to detect unusual patterns that do not conform to expected behavior. It is commonly used in fraud detection.
It models what the normal pattern looks like, and then it uses this model to detect unusual patterns.
Use Cases: Fraud detection, network security, and fault detection
3. Reinforcement Learning Algorithms
Reinforcement learning is about teaching models to make a sequence of decisions. The model learns to achieve a goal in a potentially complex and uncertain environment.
Q-learning
It is a reinforcement learning technique that helps the agent decide which action to take in each state (position in the maze) to maximize its long-term reward (reaching the goal).
- The agent maintains a Q-value for each state-action pair. This Q-value represents the expected future reward of taking a particular action in a given state.
- The agent interacts with the environment, taking actions and observing the resulting rewards.
- The Q-values are updated based on a Q-learning rule. This rule considers the current reward, the expected future reward from the next state (based on the Q-value of the best action in that state), and a learning rate.
Deep Q-Networks (DQN)
DQNs essentially replace the Q-table with a deep neural network. This network takes the current state as input and outputs the Q-values for all possible actions. The action with the highest Q-value is chosen by the agent.
DQN Training Process
- The DQN interacts with the environment, collecting experiences (state, action, reward, next state) in a replay memory.
- Random batches of experiences are sampled from the replay memory.
- The neural network is trained to predict the Q-value of the chosen action in the current state, considering the actual reward and the estimated future reward from the next state (based on the target network, a copy of the main network used for stability).
Benefits of DQNs
Handle complex state spaces: Neural networks can effectively learn patterns from high-dimensional data, making them suitable for complex environments .
Generalization: DQNs can generalize their knowledge to unseen states, allowing them to adapt to new situations.
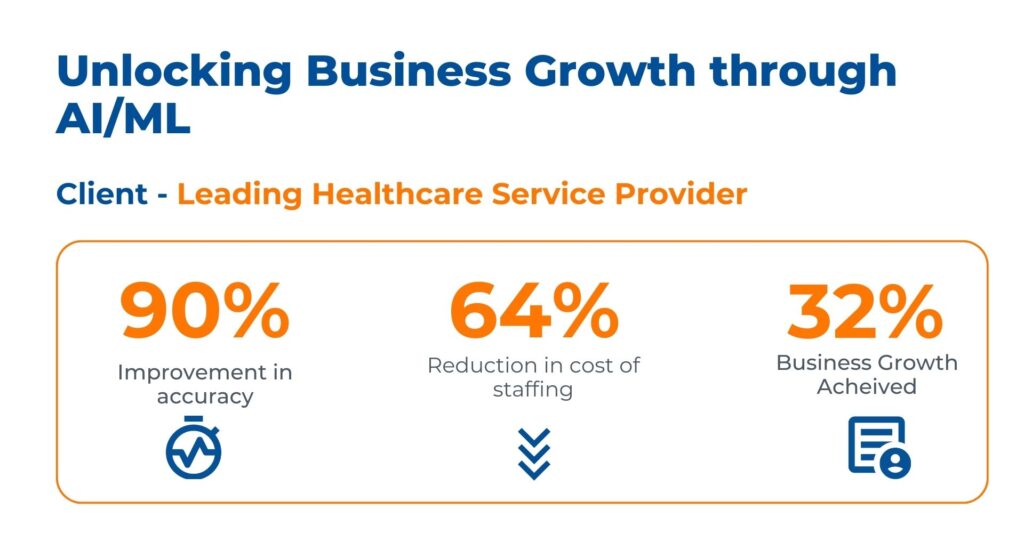
Case Study: Fueling Business Growth with AI/ML Implementation in Healthcare
Business Context
The client is a technology platform specializing in healthcare workforce optimization. They faced several challenges impeding business growth and operational efficiency, manual SOPs caused talent shortlisting delays, while document verification errors impacted service quality.
Using AI and ML, Kanerika addressed their challenges by providing the following solutions:
- Implemented AI RPA for fraud detection in insurance claim process, reducing fraud-related financial losses
- Leveraged predictive analytics, AI, NLP, and image recognition to monitor customer behavior, enhancing customer satisfaction
- Delivered AI/ML-driven RPA solutions for fraud assessment and operational excellence, resulting in cost savings
Advanced ML Algorithms
Ensemble Methods
Imagine a group of experts collaborating to solve a complex problem. Ensemble methods embody this collaborative spirit. They combine the predictions of multiple base learners (individual algorithms) to create a more robust and accurate final prediction. It’s like taking a vote among multiple experts to reach a more reliable decision.
Here’s why ensemble methods are so powerful:
Reduced Variance: By combining predictions from multiple algorithms, ensemble methods average out individual errors, leading to a more stable and less variable final outcome.
Improved Generalizability: Ensemble methods can learn from the strengths of different base learners, resulting in a model that performs well on unseen data.
Common Ensemble Techniques
Bagging (Bootstrap Aggregation): This method trains multiple models on different subsets of the original data with replacement (allowing data points to appear multiple times). The final prediction is the average of these individual predictions (for regression) or the majority vote (for classification).
Boosting: Unlike bagging, boosting trains models sequentially. Each subsequent model focuses on learning from the errors of the previous model, leading to a more refined ensemble over time. Gradient Boosting is a popular boosting technique.
Stacking: This method trains a meta-learner on top of multiple base learners. The meta-learner takes the predictions from the base learners as its input and generates the final ensemble prediction.

Neural Networks
Neural networks consist of interconnected layers of artificial neurons, where each neuron performs a simple computation on its inputs and transmits the result to the next layer. This layered structure allows neural networks to learn complex patterns and relationships within data.
This is how neural networks learn:
Data Preparation: Similar to other algorithms, data is prepared and fed into the network.
Forward Pass: The data flows through the network’s layers, with each neuron performing its activation function and passing the transformed signal forward.
Error Calculation: The network compares its output with the desired output (during training) and calculates the error.
Backward Pass: The error is then propagated backward through the network, adjusting the weights and biases of each neuron to minimize the error.
Iteration: This forward and backward pass continues iteratively, refining the network’s weights and biases as it learns from the data.
Neural Network Applications
Image Recognition: Convolutional Neural Networks (CNNs) excel at identifying objects and patterns in images. Applications range from facial recognition to medical image analysis.
Natural Language Processing (NLP): Recurrent Neural Networks (RNNs) can process sequential data like text. They are used for tasks like machine translation and sentiment analysis.
Speech Recognition: Deep learning models can be trained to recognize spoken language, enabling applications like voice assistants and automated transcription.

How Does ML Algorithms Work
1. Data Acquisition and Preparation
The fundamental component of ML algorithms is data. The algorithm’s success is highly dependent on the type and quality of data.
Data acquisition is gathering pertinent information from a variety of sources, such as sensors, databases, and user interactions.
Preparing your data is essential. This phase guarantees that the data is consistent, clean, and formatted correctly for the selected algorithm. Handling missing values, eliminating outliers, and feature scaling—making sure all features are on the same scale—may all be part of it
2. Model Selection and Training
After the data is prepared, you must select the best machine learning algorithm for the task at hand. .
Common types include:
- Using supervised learning techniques like decision trees and linear regression to estimate a target value from labeled data
- Unsupervised learning, such as Principal Component Analysis (PCA) and K-Means Clustering, involves identifying patterns in unlabeled data.
- Reinforcement learning, or trial-and-error learning, is exemplified by Q-Learning.
The prepared data is divided into training and testing data sets throughout the training phase.
The selected algorithm is fed the training data. In order to determine patterns and connections between the features (data points) and the intended output (labels in supervised learning), the algorithm examines this data. Consider a learner learning a new subject by looking at examples.
3. Model Evaluation and Tuning
After training, the model’s performance is evaluated on unseen testing data. This helps assess how well the model generalizes to new data and avoids overfitting (performing well on training data but poorly on unseen data).
Evaluation metrics vary depending on the problem type. For example, accuracy is common for classification tasks, while mean squared error is used for regression problems.
Based on the evaluation results, the model may need tuning. This involves adjusting parameters or hyperparameters to improve its performance. It’s like fine-tuning a machine to optimize its output.
4. Deployment and Monitoring
Once the model is trained, evaluated, and tuned, it’s ready for deployment. This involves integrating the model into a production environment where it can be used to make real-world predictions.
Monitoring is crucial. The model’s performance needs to be tracked over time to ensure it continues to perform well and doesn’t degrade with changes in the underlying data. Additionally, monitoring helps detect potential biases or errors in the model’s output.

Selecting the Right ML Algorithm
Choosing the right machine learning (ML) algorithm for your project can significantly impact the effectiveness and efficiency of your solution. These practical tips will help you select the most appropriate ML algorithm for your specific needs:
1. Identify Your Problem Clearly
It’s critical to know if your business problem involves anomaly detection, regression, clustering, or classification. There is a set of appropriate algorithms for every kind of problem. For classification jobs, for instance, use logistic regression or support vector machines; for regression challenges, use linear regression.
3. Consider Data Size and Quality
The choice of algorithm may be determined by the size and quality of your data. Simpler models like linear regression might work well for smaller datasets, whereas techniques like random forests or gradient boosting might work well for larger datasets. Prior to selecting an algorithm, make sure your data is clear and well-preprocessed.
3. Evaluate Algorithm Performance
Depending on the situation, different algorithms will behave differently. It’s usually a good idea to test out different algorithms and assess how well they perform using cross-validation. Considerable metrics include mean squared error for regression, F1 score for classification tasks, accuracy, precision, and recall.
4. Complexity and Scalability
Think about the algorithm’s complexity. Deep learning and other increasingly complicated algorithms demand larger amounts of data and processing power. Simpler models or ensemble methods can be a better fit if you are short on resources or need results quickly.
5. Interpretability
Select simpler-to-understand algorithms, like decision trees or linear regression, if you need to explain your model’s decisions. Interpretation can be more difficult with complex models, such as neural networks or ensemble approaches.
6. Integration and Deployment
Consider how simple it is to deploy and integrate the algorithm with your current systems. If deployment speed is a crucial consideration, your decision may be influenced by which algorithms are simpler to implement than others.

Applications of Machine Learning Algorithms
1. Recommendation Systems
Wouldn’t it be great if a streaming service put together a selection of movies that you would probably like? Machine learning algorithms-driven recommendation systems help with this. To find trends and anticipate what users might be interested in next, these algorithms analyze an enormous amount of user data, including viewing history, ratings, and demographics.
Techniques: Collaborative filtering algorithms find users that share similar preferences and suggest products that those users would like. Items that resemble ones that consumers have already interacted with are recommended using content-based filtering.
Impact: Recommendation systems enhance user experience by suggesting relevant products, movies, music, or news articles. This not only benefits users by saving them time and effort but also benefits businesses by driving engagement and sales.
2. Image Recognition
Examples of image recognition include security cameras that detect suspicious activity and your smartphone’s facial recognition feature. With remarkable precision, machine learning algorithms can identify objects, faces, and situations in digital photos and movies by extracting information from them.
Techniques: Convolutional Neural Networks (CNNs) are especially effective in image recognition applications. Their proficiency lies in recognizing patterns and obtaining features from image data.
Impact: Image recognition has a wide range of applications, including:
- Security and surveillance
- Medical image analysis for disease detection
- Autonomous vehicles navigating their surroundings
- Content moderation on social media platforms
3. Natural Language Processing
Have you ever had a conversation with a chatbot that answered your queries? This is the potential of machine learning and natural language processing (NLP). Machines can now comprehend human language, evaluate textual data, and even produce content that appears human thanks to NLP algorithms.
Techniques: Machine translation enables real-time cross-language communication, while sentiment analysis helps detect the emotional tone of a document.
Impact: NLP has numerous applications, including:
- Chatbots for customer service and technical support
- Sentiment analysis of social media data for understanding customer opinions
- Machine translation tools that break down language barriers
- Text summarization for efficiently extracting key points from large documents
5. Fraud Detection
To identify fraudulent activity such as credit card schemes and money laundering, financial institutions employ advanced machine learning algorithms. By analyzing transaction patterns, these algorithms spot irregularities and suspicious behavior that could point to fraud.
Techniques: By detecting data points that significantly differ from predicted patterns, anomaly detection algorithms can possibly find fraudulent activity.
Impact: Fraud detection algorithms help protect financial institutions and consumers from significant financial losses. They also contribute to a more secure and trustworthy financial ecosystem.
5. Spam Filtering
Ever wondered how your email provider manages to keep your inbox free of unwanted spam messages? Spam filters rely on machine learning algorithms to identify and categorize emails based on their content, sender information, and other characteristics.
Techniques: Naive Bayes classification algorithms are commonly used for spam filtering tasks. These algorithms analyze email content and compare it to predefined features of spam emails to flag them for filtering.
Impact: Spam filters significantly reduce the amount of unwanted emails reaching our inboxes, saving us time and frustration. They also help protect users from phishing attempts and other malicious email content.

Case Study: Revolutionizing Fraud Detection in Insurance with AI/ML-Powered RPA
The client is a prominent insurance provider. They wanted to move away from conventional methods requiring much manual intervention and automate their insurance claim process solution with AI/ML.
Kanerika helped them achieve their business objectives with the help of AI/ML driven RPA solutions:

Unlock Next-level Success with Kanerika’s ML Expertise
At Kanerika, we empower businesses to achieve exceptional outcomes with our cutting-edge AI and Machine Learning (ML) solutions. As a top-rated Artificial Intelligence company, we have successfully implemented numerous AI/ML projects for prestigious clients, driving business growth and enhancing operational efficiency.
Our expertise lies in leveraging advanced AI and ML technologies to analyze complex data, identify patterns, and make data-driven decisions. By integrating our innovative solutions, clients can streamline processes, improve customer experiences, and gain a competitive edge in their respective markets. With Kanerika, businesses can unlock next-level success by harnessing the power of AI and ML to drive transformational change.

Frequently Asked Questions
What is an ML algorithm?
A machine learning algorithm is a collection of mathematical instructions that computers use to learn from data. These algorithms aren't specifically designed for any one task; instead, they find patterns, anticipate outcomes, and get better over time. They are essential to the field of machine learning because they make it possible to create models that are capable of handling difficult jobs like predictive analytics, natural language processing, and picture recognition.
What are the different types of ML algorithms?
ML algorithms can be categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning uses labeled data to train models, unsupervised learning works with unlabeled data to identify patterns, and reinforcement learning involves learning through trial and error to achieve specific goals. Examples include linear regression, clustering, and Q-learning.
How are ML algorithms implemented?
Implementing machine learning (ML) algorithms requires a number of stages, including choosing the right algorithm, preparing and preprocessing the data, training the model with the method, assessing its effectiveness, and improving it for increased accuracy. Building and deploying the models in this process frequently calls for the usage of machine learning libraries like TensorFlow, scikit-learn, or PyTorch, in addition to programming languages like Python or R.
What are the applications of ML algorithms?
Numerous applications, such as recommendation systems, autonomous vehicles, image and speech recognition, and predictive analytics, use machine learning algorithms. They support businesses with fraud detection, trend forecasting, personalization of customer experiences, and task automation. By offering insights from huge datasets, these algorithms improve decision-making processes, ultimately promoting efficiency and innovation across all industries.
What are the benefits of machine learning algorithms?
Automation of repetitive processes, faster dataset analysis, and increased prediction accuracy are just a few advantages of machine learning algorithms. By providing tailored recommendations, they help businesses improve customer experiences, streamline operations, and make data-driven choices. Moreover, machine learning algorithms are flexible and dynamic, offering ongoing innovation and value.
What is the primary objective of machine learning algorithms?
Enabling computers to learn from data and make decisions or predictions without human intervention is the primary objective of machine learning algorithms. The aim of these algorithms is to develop models that perform better over time and may be applied to new data. Automating difficult tasks, improving decision-making, and promoting efficiency and creativity in a variety of fields are the ultimate objectives.

