Data is the lifeblood of a business, comprising facts, figures, and insights that fuel decision-making. Like a compass guides a traveler, data directs a company, illuminating opportunities and risks and ultimately shaping its path to success. What happens when bad data seeps into the system?
—————————————-
In 2018, a simple mistake at Samsung Securities in South Korea costed the company a staggering $300 million. During data entry, an employee accidentally entered ‘won’ instead of ‘shares,’ resulting in 1,000 Samsung Securities shares being paid out instead of 1,000 won per share in dividends. Although the error was corrected in just 37 minutes, the financial impact was significant.
This bad data example is a stark reminder of the potential financial devastation from bad data monitoring. To further demonstrate it, a recent study by Gartner concluded that every year, poor data quality costs organizations an average of $12.9 million.
Can these losses be prevented?
Are there smarter ways to work with data?
This article explores how inaccuracies and misinformed decisions can lead to substantial business losses, and how strategic use of advanced technologies can prevent such pitfalls.
Are you ready to safeguard your business against avoidable losses? Read on
Table of Contents
- What is Bad Data?
- How Bad Data Throws Businesses Off Balance
- 5 Steps to Deal with Bad Data
- How to Invest in the Right Tool
What is Bad Data?
Bad data quality refers to inaccurate, inconsistent, or misinterpreted information. It encompasses a range of issues, including outdated records, duplicate entries, incomplete information, and more. The consequences of bad data quality permeate various aspects of business operations, from marketing and sales to customer service and decision-making.
For an organization to deliver good quality data, it needs to manage and control each data storage created in the pipeline from the beginning to the end. Many organizations only care about the final data and spend time and money on quality control right before the data is delivered.
Read More: How to build a scalable data analytics pipeline
This isn’t good enough; too often, it’s too late when a problem is found. Determining where the bad quality came from takes a long time, or fixing the pain becomes too expensive and time-consuming. But if a company can manage the quality of each dataset as it is created or received, the quality of the data is guaranteed.
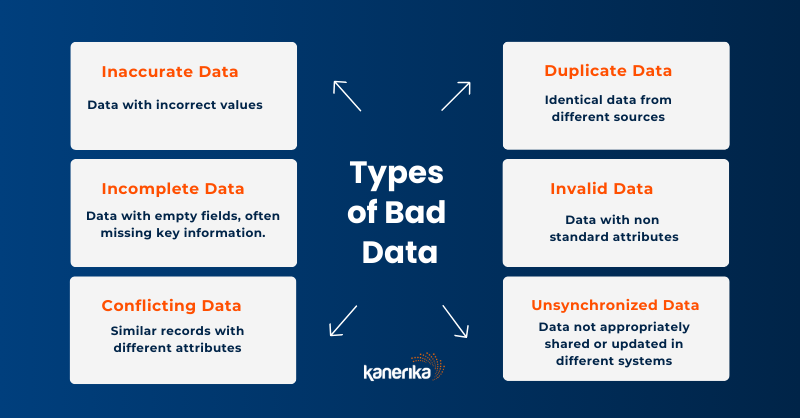
Poor data quality can spell trouble for businesses, impacting decisions and operations. Embracing advanced technologies to mitigate these risks is crucial for success in the digital era.
Discover how Kanerika, a trailblazer in technological innovation, empowered a global healthcare provider with new data architecture to deliver self-care to remote patients.
How bad data throws businesses off balance
Misguided Decision-Making
When businesses set their goals and targets every year, they rely on making smart, informed decisions. Now, picture a retail company without accurate data on what products are flying off the shelves and which are barely moving.
Their choices, like what to showcase prominently and what to discount, are make-or-break decisions. It’s all about striking that balance between boosting profits and cutting losses.
But here’s the thing: In today’s cutthroat market, you can’t just survive – you need to thrive. And that’s impossible without the right information and insights to drive your actions.
Flip – the ultimate solution to all your data woes

Ready to see FLIP in action? Schedule a demo call today!
Ineffective Marketing Campaigns
Can you imagine a marketing team trying to fire off promotional emails using a database with more holes than Swiss cheese? Or, even worse, pumping millions into campaigns without crucial data on age, gender, and occupation?
The result? Customers getting hit with offers that are about as relevant as a snowstorm in summer. And what do companies get? A whopping dent in their marketing budget, all for something that was pretty much doomed from the start.
Customer Dissatisfaction
Bad data has and will continue to lead to widespread customer dissatisfaction. Take, for instance, a recent incident where thousands of passengers were left stranded at airports due to a data failure. This mishap, acknowledged by National Air Traffic Services, marked a significant blunder in the aviation industry. The result? Customers worldwide faced immense inconvenience and added stress.
“It takes 20 years to build a reputation and five minutes to ruin it.
If you think about that, you’ll do things differently.”
– Warren Buffet
Legal and Compliance Risks
In regulated industries like finance, healthcare, and GDPR-affected sectors, inaccurate data can lead to non-compliance with legal requirements. For example, incorrect financial reporting due to poor data quality can result in regulatory fines. Similarly, mishandling sensitive customer information, such as personal or financial data, due to bad data practices can lead to data breaches.
The Facebook data leak is a stark reminder of the legal and compliance risks of mishandling data. The company paid a record $5 billion fine to the Federal Trade Commission as a settlement for the data breach – one of the largest penalties ever imposed for a privacy violation. This incident underscores the critical importance of robust data protection measures and regulatory compliance for businesses relying heavily on data.

5 steps to deal with bad data quality
Data Profiling
In any organization, a substantial portion of data originates from external sources, including data from other organizations or third-party software. It’s essential to recognize and separate bad quality data from good data. Conducting a comprehensive data quality assessment on data in and data out is, therefore, of paramount importance.
A reliable data profiling tool plays a pivotal role in this process. It meticulously examines various aspects of the incoming data, uncovering potential anomalies, discrepancies, and inaccuracies. An organization can streamline data profiling tasks by dividing them into two sub-tasks:
Proactive profiling over assumptions: All incoming data should undergo rigorous profiling and verification. This helps align with established standards and best practices before being integrated into the organizational ecosystem.
Centralized oversight for enhanced data quality: Establishing a comprehensive data catalog and a Key Performance Indicator (KPI) dashboard is instrumental. This centralized repository serves as a reference point, meticulously documenting and monitoring the quality of incoming data.
Dealing with duplicate data
Duplicate Data, a common challenge in organizations, arises when different teams or individuals use identical data sources for distinct purposes downstream. This can lead to discrepancies and inconsistencies, affecting multiple systems and databases. Correcting such data issues can be a complex and time-consuming task.
To prevent this, a data pipeline must be well specified and properly developed in data assets, data modeling, business rules, and architecture. Effective communication promotes and enforces data sharing across the company, which improves overall efficiency and reduces data quality issues caused by data duplications. To prevent duplicate data, three sections must be established:
- A data governance program that establishes dataset ownership and supports sharing to minimize department silos.
- Regularly examined and audited data asset management and modeling.
- Enterprise-wide logical data pipeline design.
- Rapid platform changes require good data management and enterprise-level data governance for future migrations.
Accurate gathering of data requirement
Accurate data requirement gathering serves as the cornerstone of data quality. It ensures that the data delivered to clients and users aligns precisely with their needs, setting the stage for reliable and meaningful insights. But all this may not be as easy as it sounds, because of the following reasons:
- Data presentation is difficult.
- Understanding a client’s needs requires data discovery, analysis, and effective communication, frequently via data samples and visualizations.
- The criteria are incomplete if all data conditions and scenarios aren’t specified.
- The Data Governance Committee should also need clear, easy-to-access requirements documentation.
The Business Analyst’s expertise in this process is invaluable, facilitating effective communication and contributing to robust data quality assurance. Their unique position, with insights into client expectations and existing systems, enables them to bridge communication gaps effectively. They act as the liaison between clients and technical teams. Additionally, they collaborate in formulating robust test plans to ensure that the produced data aligns seamlessly with the specified requirements.
Enforcement of data integration
Using foreign keys, checking constraints, and triggers to ensure data is correct is an integral part of a relational database. When there are more data sources and outputs and more data, not all datasets can live in the same database system. So, the referential integrity of the data needs to be enforced by applications and processes, which need to be defined by best practices of data governance and included in the design for implementation.
Referential enforcement is getting harder and more complex in today’s big data-driven world. Failing to prioritize integrity from the outset can lead to outdated, incomplete, or delayed referenced data, significantly compromising overall data quality. It’s imperative to proactively implement and uphold stringent data integration practices for robust and accurate data management.
Capable data quality control teams
In maintaining high-quality data, two distinct teams play crucial roles:
Quality assurance (QA): This team is responsible for safeguarding the integrity of software and programs during updates or modifications. Their rigorous change management processes are essential in ensuring data quality, particularly in fast-paced organizations with data-intensive applications. For example, in an e-commerce platform, the QA team rigorously tests updates to the website’s checkout process to ensure it functions seamlessly without data discrepancies or errors.
Production quality control: This function may be a standalone team or integrated within the Quality Assurance or Business Analyst teams, depending on the organization’s structure. They possess an in-depth understanding of business rules and requirements. They are equipped with tools and dashboards to identify anomalies, irregular trends, and any deviations from the norm in production. In a financial institution, for instance, the Production Quality Control team monitors transactional data for any irregularities, ensuring accurate financial records and preventing potential discrepancies.
The combined efforts from both teams ensure that data remains accurate, reliable, and aligned with business needs, ultimately contributing to informed decision-making and dataops excellence. Integrating AI technologies further augments their capabilities, enhancing efficiency and effectiveness in data quality assurance practices.
Read More: Why is Automating Data Processes Important?
Investing in the right tool can help you save millions a year…
In today’s data-driven landscape, the importance of high-quality data cannot be overstated. As businesses increasingly recognize the perils of poor data quality, they are also embracing a range of innovative tools to streamline their data operations.
FLIP, an AI-powered and no-code interface, data operations platform, offers a holistic solution to automate and scale data transformation processes. Here’s how FLIP can help your businesses thrive in the data-driven world…
Experience Effortless Automation: Say goodbye to manual processes and let FLIP take charge. It streamlines the entire data transformation process, liberating your time and resources for more critical tasks.
No Coding Required: No coding skills? No problem! FLIP’s user-friendly interface empowers anyone to effortlessly configure and customize their data pipelines, eliminating the need for complex programming.
Seamless Integration: FLIP effortlessly integrates with your current tools and systems. Our product ensures a smooth transition with minimal disruption to your existing workflow.
Real-time Monitoring and Alerting: FLIP offers robust real-time monitoring of your data transformation. Gain instant insights, stay in control, and never miss a beat.
Built for Growth: As your data requirements expand, FLIP grows with you. It’s tailored to handle large-scale data pipelines, accommodating your growing business needs without sacrificing performance.
Read how the deployment of FLIP for a Telemetry Analysis Platform resulted in enhanced performance, reduced delays, and cost savings.
To experience FLIP, Sign up now for a free account today!

FAQs
How much does bad data cost a company?
Bad data can be costly for businesses. According to a study by Gartner, poor data quality costs organizations an average of $12.9 million annually. However, the actual cost can vary widely depending on the company's size, industry, and how bad data impacts operations and decision-making processes.
Where does bad data come from?
Bad data can originate from various sources, including manual data entry errors, outdated information, incomplete records, duplicate entries, and data collected from unreliable or unverified sources. It can also result from system glitches, integration issues, or failure to update databases with accurate and current information.
How is bad data detected?
Bad data can be detected through data quality checks and validation processes. This may involve data profiling tools to identify inconsistencies, anomalies, and inaccuracies. Additionally, businesses employ data cleansing techniques to rectify errors, eliminate duplicates, and ensure data accuracy. Regular audits and validation checks are essential for maintaining data quality.

